
# Database Guidelines
These guidelines are followed by all members of PLUSTEAM and have been implemented in every project that makes use of a database.
# General
Do
- Use consistent and descriptive identifiers and names.
- Make judicious use of white space and indentation to make code easier to read.
- Store ISO-8601 compliant time and date information (YYYY-MM-DD HH:MM:SS.SSSSS).
- Try to use only standard SQL functions instead of vendor specific functions for reasons of portability.
- Keep code succinct and devoid of redundant SQL—such as unnecessary quoting or parentheses or WHERE clauses that can otherwise be derived.
- Include comments in SQL code where necessary. Use the C style opening /* and closing */ where possible otherwise precede comments with -- and finish them with a new line.
Avoid
- CamelCase—it is difficult to scan quickly.
- Descriptive prefixes or Hungarian notation such as sp_ or
tbl. - Plurals—use the more natural collective term where possible instead. For example staff instead of employees or people instead of individuals.
- Quoted identifiers—if you must use them then stick to SQL92 double-quotes for portability (you may need to configure your SQL server to support this depending on the vendor).
- Object-oriented design principles should not be applied to SQL or database structures.
# Naming conventions
General
- Ensure the name is unique and does not exist as a reserved keyword.
- Keep the length to a maximum of 30 bytes—in practice this is 30 characters unless you are using multi-byte character set.
- Names must begin with a letter and may not end with an underscore.
- Only use letters, numbers and underscores in names.
- Avoid the use of multiple consecutive underscores—these can be hard to read.
- Use underscores where you would naturally include a space in the name (the first name becomes first_name).
- Avoid abbreviations and if you have to use them make sure they are commonly understood.
Tables
- Use a collective name or, less ideally, a plural form. For example (in order of preference) staff and employees.
- Do not prefix with
tblor any other such descriptive prefix or Hungarian notation. - Never give a table the same name as one of its columns and vice versa.
- Avoid, where possible, concatenating two table names together to create the name of a relationship table. Rather than cars_mechanics prefer services.
Columns
- Always use the singular name.
- Where possible avoid simply using id as the primary identifier for the table.
- Do not add a column with the same name as its table and vice versa.
- Always use lowercase except where it may make sense not to such as proper nouns.
Aliasing or correlations
- Should relate in some way to the object or expression they are aliasing.
- As a rule of thumb, the correlation name should be the first letter of each word in the object’s name.
- If there is already a correlation with the same name then append a number.
- Always include the AS keyword—makes it easier to read as it is explicit.
- For computed data (SUM() or AVG()) use the name you would give it was it a column defined in the schema.
Stored procedures
- The name must contain a verb.
- Do not prefix with sp_ or any other such descriptive prefix or Hungarian notation.
Uniform suffixes
The following suffixes have a universal meaning ensuring the columns can be read and understood easily from SQL code. Use the correct suffix where appropriate.
- _id: a unique identifier such as a column that is a primary key.
- _status: flag value or some other status of any type such as publication_status.
- _total: the total or sum of a collection of values.
- _num: denotes the field contains any kind of number.
- _name: signifies a name such as first_name.
- _seq: contains a contiguous sequence of values.
- _date: denotes a column that contains the date of something.
- _tally: a count.
- _size: the size of something such as file size or clothing.
- _addr: an address for the record could be physical or intangible such as ip_addr.
# Query syntax
Reserved words
Always use uppercase for the reserved keywords like SELECT and WHERE.
It is best to avoid the abbreviated keywords and use the full-length ones where available (prefer ABSOLUTE to ABS).
Do not use database server-specific keywords where an ANSI SQL keyword already exists performing the same function. This helps to make code more portable.
White space
To make the code easier to read it is important that the correct compliment of spacing is used. Do not crowd code or remove natural language spaces.
Spaces should be used to line up the code so that the root keywords all end on the same character boundary. This forms a river down the middle making it easy for the reader's eye to scan over the code and separate the keywords from the implementation detail. Rivers are bad in typography, but helpful here.
Although not exhaustive always include spaces:
- Before and after equals (=)
- after commas (,)
- surrounding apostrophes (') not within parentheses or with a trailing comma or semicolon.
Always include newlines/vertical space:
- before AND or OR
- after semicolons to separate queries for easier reading
- after each keyword definition
- after a comma when separating multiple columns into logical groups
- to separate code into related sections, which helps to ease the readability of large chunks of code.
- Keeping all the keywords aligned to the righthand side and the values left aligned creates a uniform gap down the middle of the query. It makes it much easier to scan the query definition over quickly too.
Indentation
To ensure that SQL is readable it is important that standards of indentation are followed.
Joins should be indented to the other side of the river and grouped with a new line where necessary.
Subqueries should also be aligned to the right side of the river and then laid out using the same style as any other query. Sometimes it will make sense to have the closing parenthesis on a new line at the same character position as it’s the opening partner—this is especially true where you have nested subqueries.
Preferred formalisms
- Make use of BETWEEN where possible instead of combining multiple statements with AND.
- Similarly use IN() instead of multiple OR clauses.
- Where a value needs to be interpreted before leaving the database use the CASE expression. CASE statements can be nested to form more complex logical structures.
- Avoid the use of UNION clauses and temporary tables where possible. If the schema can be optimized to remove the reliance on these features then it most likely should be.
# Query performance
EXPLAIN command (PostgreSQL)
Before deploying a query into any application, it’s a good practice to run it into the EXPLAIN command, it shows the query planner
to choose good plans and improve the performace, all it does is an estimated execution plan based on the available statistics.
This means the actual plan can differ quite a bit.
Every query plan consists of nodes. Nodes can be nested, and are executed from the inside out. Nodes are indicated using a -> followed
by the type of node taken, like follows.
Aggregate (cost=7.42..7.43 rows=1 width=32)
-> Nested Loop Left Join (cost=3.86..7.40 rows=1 width=136)
-> Nested Loop Left Join (cost=0.00..3.51 rows=1 width=104)
Join Filter: (distinction.characteristic_id = characteristic.id)
-> Nested Loop Semi Join (cost=0.00..2.44 rows=1 width=76)
Join Filter: (distinction.id = _0__be_0_public_distinction_value.distinction_id)
-> Seq Scan on distinction (cost=0.00..1.32 rows=1 width=76)
Filter: (characteristic_id = 1)
2
3
4
5
6
7
8
Let’s see a simple example
EXPLAIN SELECT * FROM tenk1 WHERE unique1 < 7000;
QUERY PLAN
------------------------------------------------------------------
Seq Scan on tenk1 (cost=0.00..483.00 rows=7001 width=244)
Filter: (unique1 <7000)
2
3
4
5
6
Here just exists one node (Seq Scan), the Filter is an additional filter applied to the results of the node, this plan takes the rows scanned, apply the filter and produces a new list of rows. It shows a set of statistics on every node like cost, rows and width.
The cost, or penalty points, is mostly an abstract concept in PostgreSQL. There are many ways in which PostgreSQL can execute a query, and PostgreSQL always chooses the execution plan with the lowest possible cost value. The most important thing is it specifies how expensive a node was. The format of the cost field is STARTUP COST..TOTAL COST
The startup cost states how expensive it was to start the node, with the total cost describing how expensive the entire node was. In general: the greater the values, the more expensive the node. All this is computed with planner’s cost parameters
(disk pages read * seq_page_cost) + (rows scanned * cpu_tuple_cost) + (rows scanned * cpu_operator_cost)By default,
seq_page_costis 1.0,cpu_tuple_costis 0.01 andcpu_operator_costis 0.0025. All these are PostgreSQL parameters.Rows: This is the estimated number of rows output to be returned
Width: This is the estimated size in bytes of the returned rows
The very first line (the summary line for the topmost node) has the estimated total execution cost for the plan; it is this number that the planner seeks to minimize, in this example is 483.00
NOTES:
- When using just
EXPLAIN, PostgreSQL won’t actually execute the query - When using
EXPLAIN ANALIZE, PostgreSQL execute the query as well - It's important to understand that the cost of an upper-level node includes the cost of all its child nodes
- The cost does not consider the time spent transmitting result rows to the client.
- The data on every database are all divide exactly by
8192 (8k). This is because PostgreSQL (by default) writes blocks of data (what PostgreSQL calls pages) to disk in 8k chunks. If you have a large table that has more than 1GB of data in it, you will see multiple files with the same number appended with .1 .2 .3 and so on - On the GraphiQL tab (Hasura) you can find an option to analize the queries
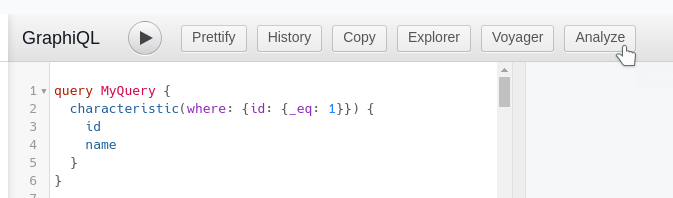
It will show you the Generated SQL and the Execution Plan of the query
Generated SQL
SELECT
coalesce(json_agg("root"), '[]') AS "root"
FROM
(
SELECT
row_to_json(
(
SELECT
"_1_e"
FROM
(
SELECT
"_0_root.base"."id" AS "id",
"_0_root.base"."name" AS "name"
) AS "_1_e"
)
) AS "root"
FROM
(
SELECT
*
FROM
"public"."characteristic"
WHERE
(
("public"."characteristic"."id") = (('10') :: integer)
)
) AS "_0_root.base"
) AS "_2_root"
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
Execution plan
Aggregate (cost=1.07..1.08 rows=1 width=32)
-> Seq Scan on characteristic (cost=0.00..1.05 rows=1 width=72)
Filter: (id = 10)
SubPlan 1
-> Result (cost=0.00..0.01 rows=1 width=32)
2
3
4
5
For more information:
- Reading an explain analyze query plan
- Using explain
- The PostgreSQL query cost model
- Understanding explain plans
# Examples
Modeling
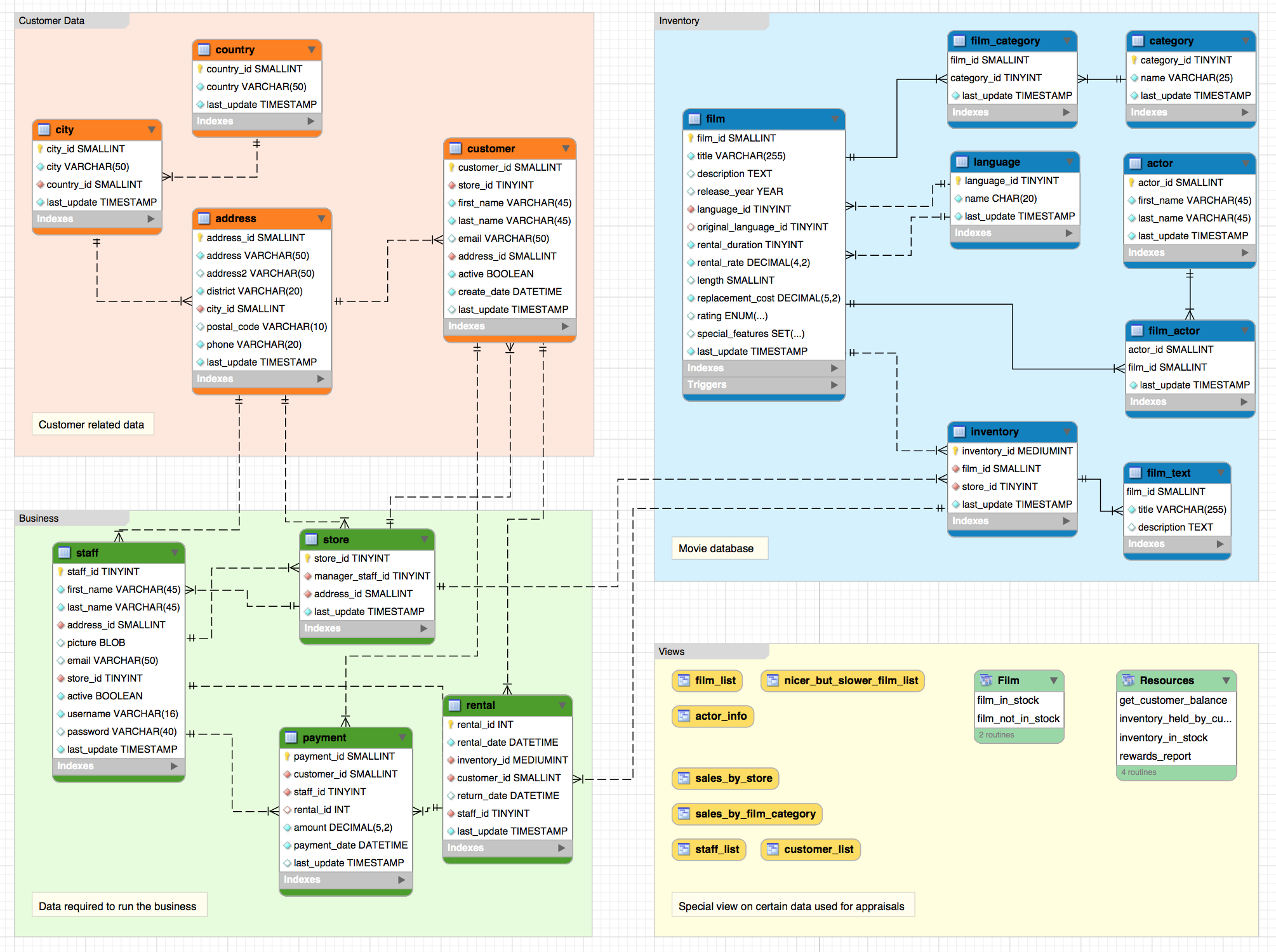
Queries
WHEN 'BN1' THEN 'Brighton'
WHEN 'EH1' THEN 'Edinburgh'
END AS city
FROM office_locations
WHERE country = 'United Kingdom'
AND opening_time BETWEEN 8 AND 9
AND postcode IN ('EH1', 'BN1', 'NN1', 'KW1')
2
3
4
5
6
7
# Data Dictionary
Is used to catalog and communicate the structure and content of data, and provides meaningful descriptions for named data objects.
Data Dictionaries are Used for
- Documentation
- Communication
- Application Design
- System Analysis
- Data Integration
- Decision Making
It is not necessary to produce separate documentation for each implementation.
# Advantages
Data Dictionaries are for Sharing
Facilitates standardization by documenting common data structures
Keep Your Data Dictionary Up to Date
Plan ahead for storing data at the start of any project by developing a schema or data model as a guide to data requirements.
Data Dictionaries Can Reveal Poor Design Decisions
Poor table organization and object naming can limit data understandability and ease-of-use, incomplete data definitions can render an otherwise stellar dataset useless, and failure to keep the dictionary up to date with the actual data structures suggests a lack of data stewardship.
Making a Data Dictionary
Most database management systems have built-in, active data dictionaries and can generate documentation as needed. The same is true when designing data systems using CASE tools.
Example of a Data Dictionary
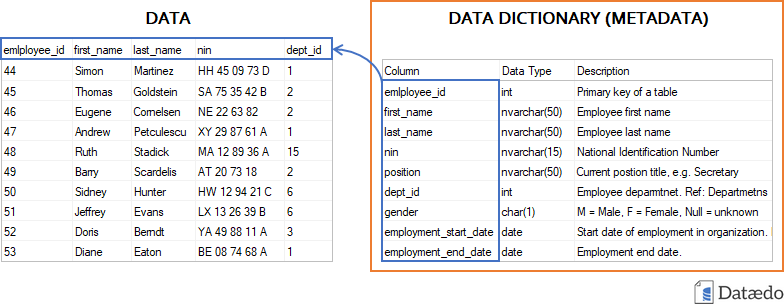
You are probably wondering how all of this comes together.
Here’s a look at a simplified example data dictionary
# PLUSTEAM Standard
In Plusteam depending on the case we use
# Vertabelo
Vertabelo is a DB modeling tool that generates data dictionary in different formats
# Word document
Pros:
- The document generated can be used for formal presentations.
Cons:
- Can't search the information easily

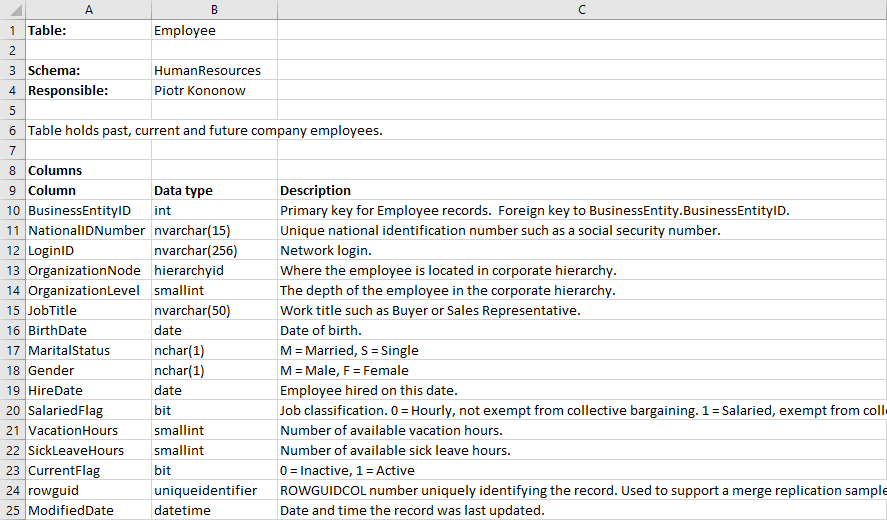
# Excel Spreadsheet
Pros:
- Use filters to analyze data
- Tabular Information
- Use text fields with validation and other advantages of Excel
Cons:
- Not a formal document
Conclusion
Ideally we use Vertabelo, that allow us to have the model and export it to anything.
In general, word to make a presentations and excel to take advantage of filters with big databases
for more information: